










BeingBeyond最新发布:百万规模数据集,实现精细动作跨平台、跨形态动作迁移

日期:2026.01.19

浏览量: 434
近日,北京大学、中国人民大学的科研团队,在通用人形机器人动作生成技术上取得了突破性进展:首次提出具有数据‑模型协同放量(Scaling Law)特性的通用动作生成框架 Being‑M0,并围绕其构建了一套完整的“数据–模型–迁移”技术体系,为人形机器人实现灵活、多样的运动控制开辟了新路径。
Being‑M0论文封面
为实现这一目标,研究团队首先从海量互联网视频中自动化提取、标注并清洗,构建了业界首个百万量级的动作生成数据集 MotionLib。该数据集的规模达到现有最大公开数据集的15倍以上,为训练高性能动作生成模型提供了坚实的数据基础。
在此基础上,团队研发了端到端的文本驱动动作生成模型,验证了在动作生成领域中“大数据 + 大模型”的技术可行性,并成功将生成的人体动作高效迁移至多款人形机器人平台,实现了从文本指令到机器人动作的完整闭环。
该项研究成果已被人工智能顶级会议 ICML 2025 接收。
百万级动作数据集MotionLib:突破数据规模瓶颈
在AI领域,数据规模往往是模型性能跃升的关键。为了构建高质量、大规模的动作数据资源,研究团队从公开数据集及在线视频平台系统采集了超2000万段人体动作视频,并开发了一套全自动数据处理流水线。该流水线通过预训练模型进行2D人体关键点估计与筛选,再借助在大规模3D数据上训练的模型提取高精度3D关键点信息。
MotionLib 数据集示例
针对以往动作数据标注粒度粗糙的问题,团队提出了分层细粒度标注方案,利用大语言模型为每段视频生成结构化描述,不仅涵盖整体动作语义,还详细记录手臂、腿部等局部运动特征,为精细化动作生成提供了重要支持。
此外,MotionLib 还具备多模态特性,除常规RGB视频外,还包含深度信息,并支持多人交互场景,极大拓展了数据集的适用范围。经过严格的质量过滤,最终建成包含超百万条高质量动作序列的数据集,为动作生成领域的进一步突破奠定了数据基础。
大规模动作生成模型,实现从语言到动作的精准映射
随着MotionLib数据规模实现数量级增长,如何充分发挥大数据效能成为关键。
通过系统实验,团队首次在动作生成领域验证了数据规模与模型规模之间的协同放量规律(Scaling Law)。实验表明,在同等数据条件下,更大容量的模型(如13B参数的LLaMA‑2)在动作多样性、语义对齐等方面显著优于较小模型(如700M参数的GPT2),并且大模型展现出更优的数据利用效率。
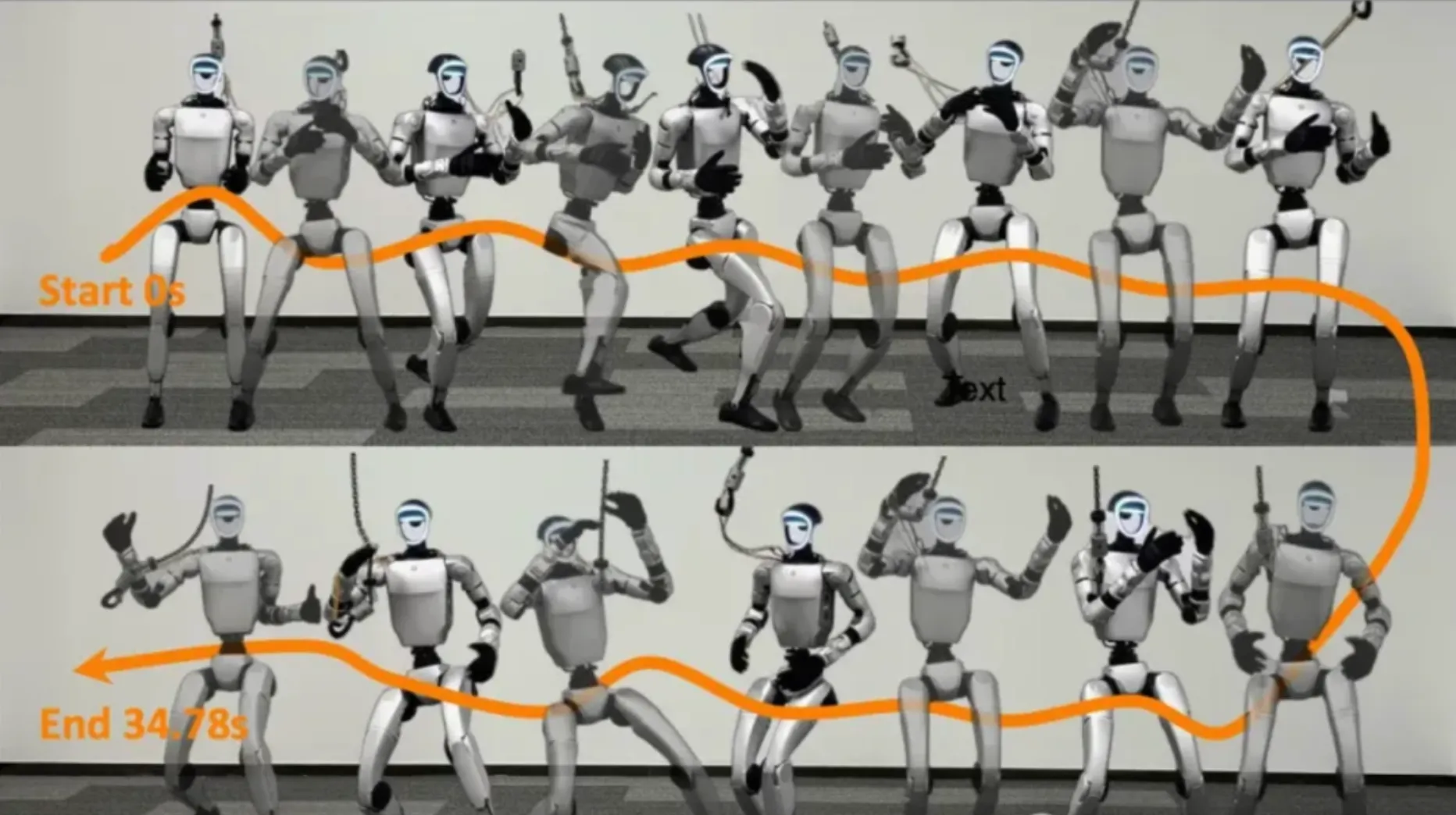
高效动作重定向,从人体到人形机器人
将生成的人体动作迁移到实体机器人是实现文本驱动人形机器人动作生成的最后一环。实现文本到机器人动作的闭环需要解决跨形态动作迁移这一核心挑战。
由于不同人形机器人在自由度配置、连杆尺寸等方面存在显著差异,将人体动作重定向到机器人时,传统基于运动学逆解或关节角度直接映射的方法往往导致动作失真甚至动力学不可行。
Being-M0整体框架分为两个阶段
为解决这一问题,Being-M0团队提出了”优化+学习”的两阶段解决方案:
在训练数据构建阶段,通过多目标优化方法生成满足机器人运动学约束的动作序列——优化过程不仅考虑了关节限位等基本约束,还考虑了动作轨迹的平滑性和稳定性。这种基于多目标优化的方法虽然计算开销较大,但能保证生成数据的高质量,为后续的学习阶段打下良好基础。
在动作映射阶段,采用轻量级的MLP网络学习从人体动作到人形机器人动作的映射关系。通过精心设计的网络结构,该方法实现了对H1、H1-2、G1等多个机器人平台的高效支持。
与直接优化相比,基于神经网络的方法显著提升了系统的实时性能,同时保持了动作迁移的准确性。
项目地址:https://beingbeyond.github.io/Being-M0/
论文链接:https://arxiv.org/abs/2410.03311
关于BeingBeyond智在无界:
BeingBeyond开创了利用大规模人类数据训练通用具身模型的范式,灵巧手操作模型(Being-H系列)以及人形机器人移动操作模型(Being-M系列)均具备行业领先性能,且可以跨本体部署。同时,团队构建的全球最大第一视角手部数据集和全身姿态数据集,正在成为驱动模型迭代的核心基础。BeingBeyond专注通用人形机器人模型研发,为机器人本体厂商及落地场景客户提供强泛化、可落地的具身模型。












京公网安备11010802047405号